Dataset Management
Hier haben sie die möglichkeit:
➤ Konnektoren anzulegen
➤ Datensätze zu verwalten
Konnektoren
Überblick
Konnektoren verbinden Silent AI mit externen Datenquellen.
Über sie können Inhalte aus angebundenen Systemen in Datasets integriert und für Abfragen genutzt werden.
Der Zugriff erfolgt über das “Konnektoren und Datensätze” Menü (oben rechts) → „Konnektoren“.
Konnektor-Übersicht
Nach dem Öffnen des Bereichs gelangen Sie zur Konnektor-Übersicht.
Hier sehen Sie:
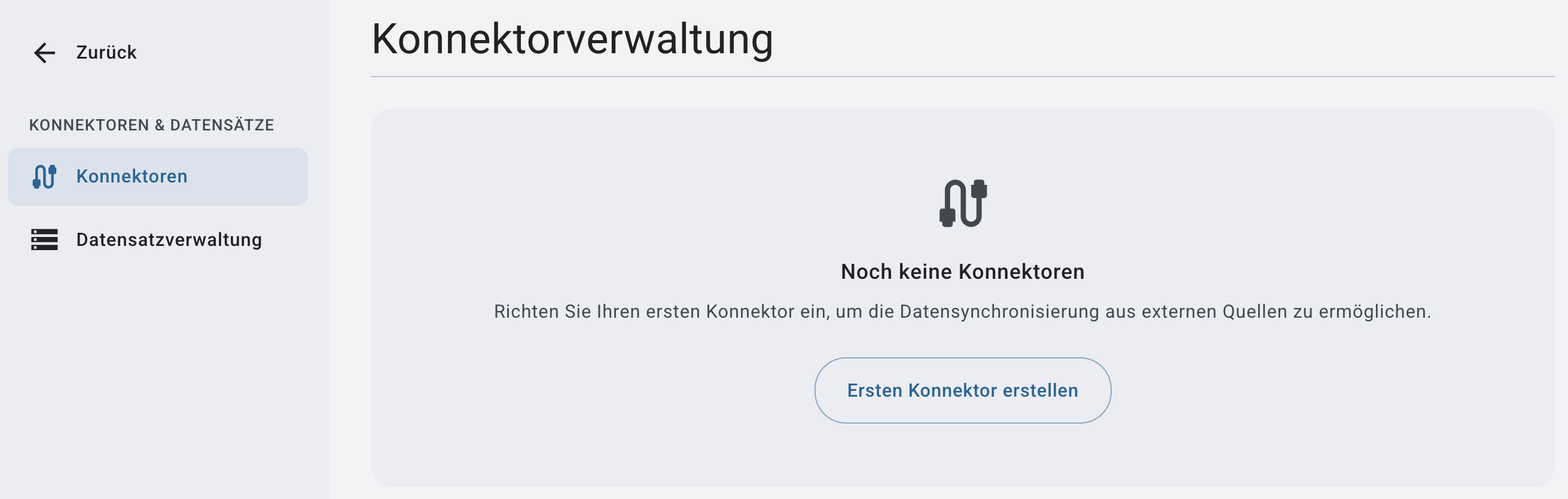
➤ Bereits eingerichtete Konnektoren (falls vorhanden)
➤ Die Möglichkeit, neue Konnektoren hinzuzufügen
Sind noch keine Konnektoren eingerichtet, erscheint eine Hinweisfläche mit der Möglichkeit, den ersten Konnektor anzulegen.
Neuen Konnektor hinzufügen
Um eine neue Datenquelle anzubinden, klicken Sie auf:
➤ „+ Konnektor hinzufügen“
oder – bei leerer Übersicht – auf
➤ „Ersten Konnektor erstellen“
Anschließend öffnet sich ein Auswahlfenster.
Konnektortyp auswählen
Im Auswahlfenster wählen Sie den gewünschten Konnektortyp aus.
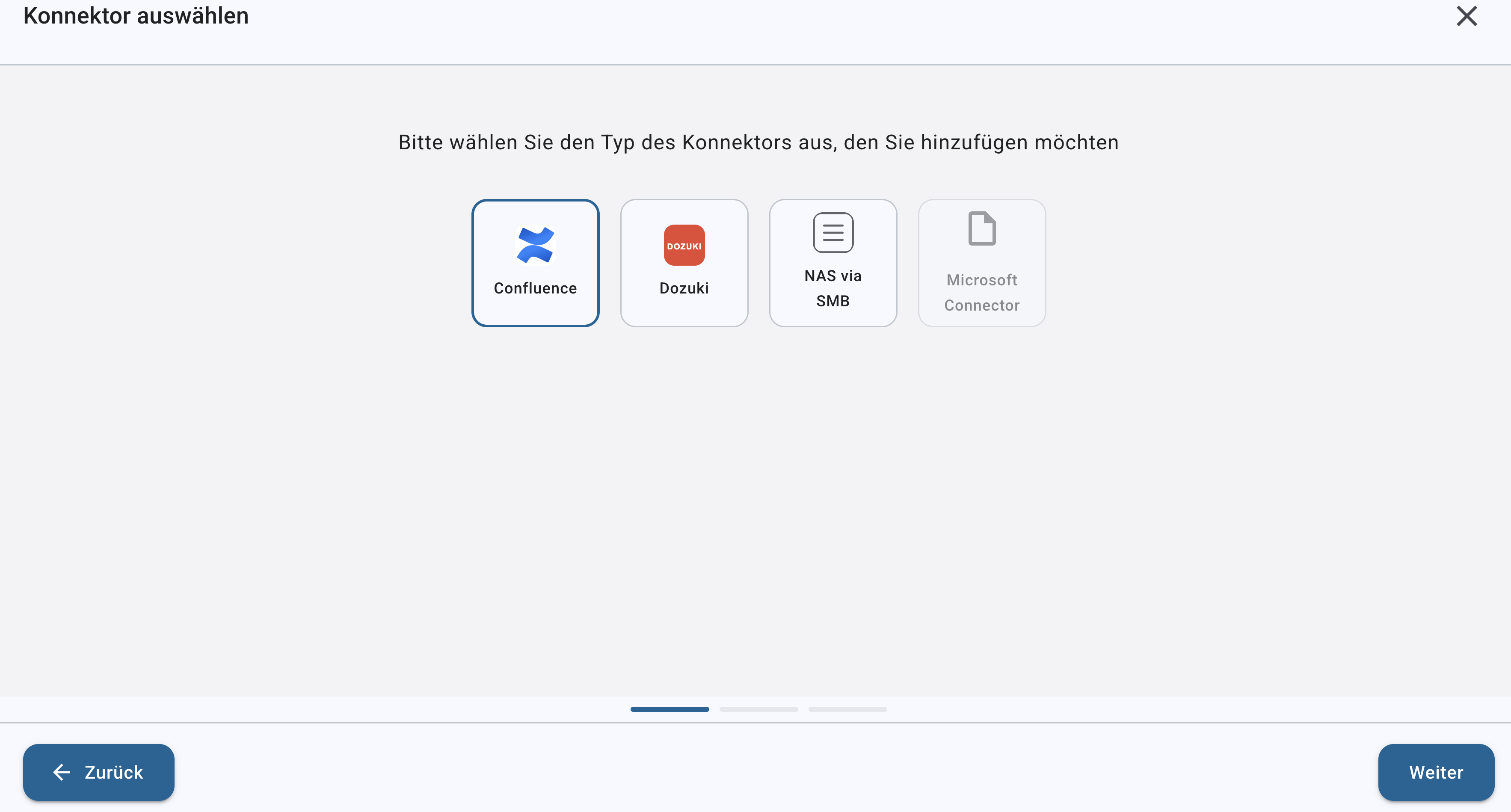
Verfügbare Konnektortypen:
➤ Confluence
➤ Dozuki
➤ NAS via SMB
Je nach ausgewähltem Typ werden anschließend spezifische Verbindungsparameter abgefragt (z. B. Serveradresse, Zugangsdaten oder API-Informationen).
Allgemeiner Ablauf zur Einrichtung
➤ Konnektortyp auswählen
➤ Verbindungsdaten eingeben
➤ Berechtigungen festlegen
➤ Speichern
Nach erfolgreicher Einrichtung erscheint der Konnektor in der Übersicht und kann für die Erstellung von Datasets verwendet werden.
Confluence
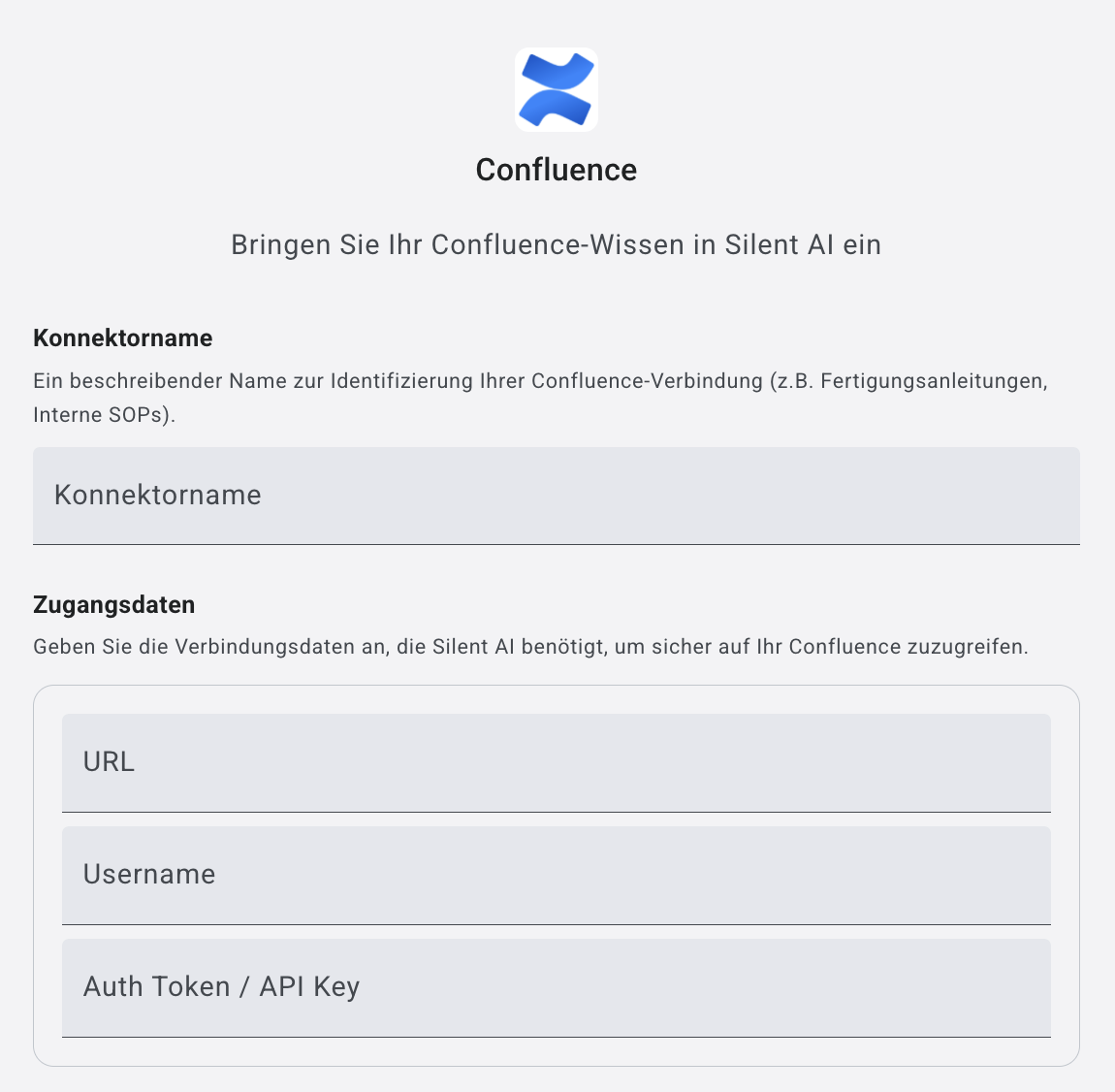
➤ Name: Geben Sie ihrem Konnektor einen Namen
Zugangsdaten
➤ URL:
Vollständige Webadresse inkl. Pfad: - Cloud: https://firma.atlassian.net/wiki - On-Premise: https://confluence.firma.de/
Wenn der ausgewählte Space Seiten mit Zugriffsbeschränkungen enthält und diese Inhalte über den Konnektor erfasst werden sollen, stellen Sie bitte sicher, dass der API-User in Confluence Zugriff auf diese Seiten erhält.
➤ Username:
Benutzername bzw. E-Mail-Adresse des Confluence-Kontos, das für den Zugriff verwendet wird.
➤ Auth Token / API Key:
Persönlicher API-Token zur sicheren Authentifizierung. Dieser wird im Confluence-/Atlassian-Konto generiert und ersetzt das Passwort bei API-Zugriffen.
Dozuki
➤ Name: Geben Sie ihrem Konnektor einen Namen
Zugangsdaten
➤ Auth Token / API Key:
Authentifizierungstoken für den API-Zugriff. Der Token wird über die Dozuki Authentication API generiert (Login-Endpoint). Hinweis: Je nach Konfiguration der Dozuki-Instanz kann zusätzlich eine App-ID erforderlich sein – diese beim Site-Administrator anfragen.
NAS via SMB
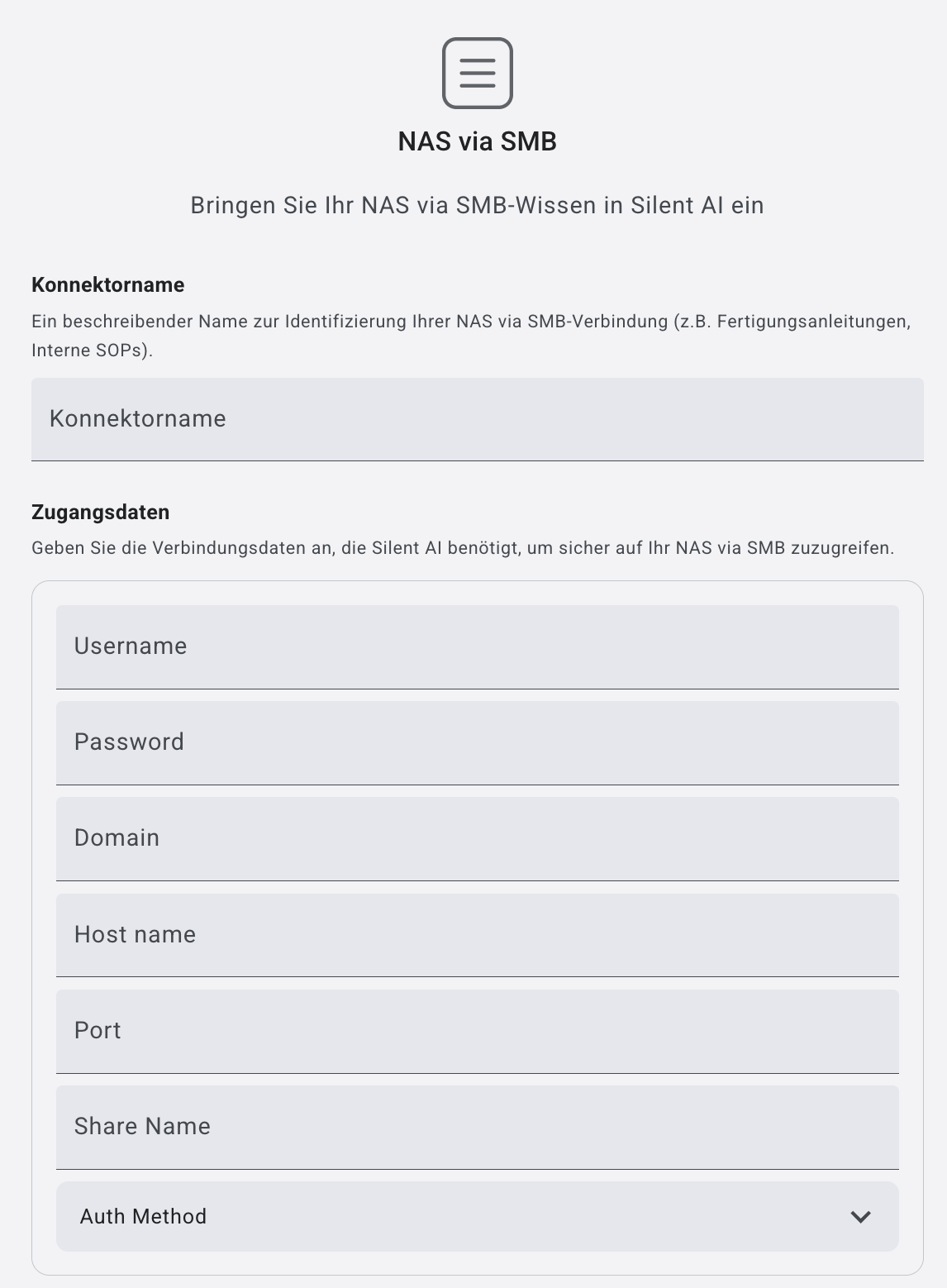
➤ Name: Geben Sie ihrem Konnektor einen Namen
Zugangsdaten
➤ Username:
Benutzername eines Kontos, das Zugriff auf die Freigabe (Share) des NAS-Systems besitzt. (AD login)
➤ Password:
Passwort des angegebenen Benutzers zur Authentifizierung am NAS.
➤ Domain:
Netzwerk- oder Active-Directory-Domain, zu der der Benutzer gehört. (optional)
➤ Host name:
Netzwerkname oder IP-Adresse des NAS-Servers (z. B. nas01.firma.local oder 192.168.1.10).
➤ Port:
Netzwerkport, über den der SMB-Dienst erreichbar ist. Standardmäßig ist dies Port 445.
➤ Share Name:
Name der freigegebenen Ordnerstruktur auf dem NAS, auf die zugegriffen werden soll (z. B. Dokumente oder Projekte).
➤ Auth Method:
Authentifizierungsmethode, die für die Anmeldung verwendet wird (z. B. NTLM, Kerberos oder automatische Aushandlung je nach Serverkonfiguration).
Berechtigungen
Bei der Erstellung eines Konnektors haben Sie außerdem die Möglichkeit bestimmten Nutzern Zugriff auf ihren Konnektor zu gewähren.
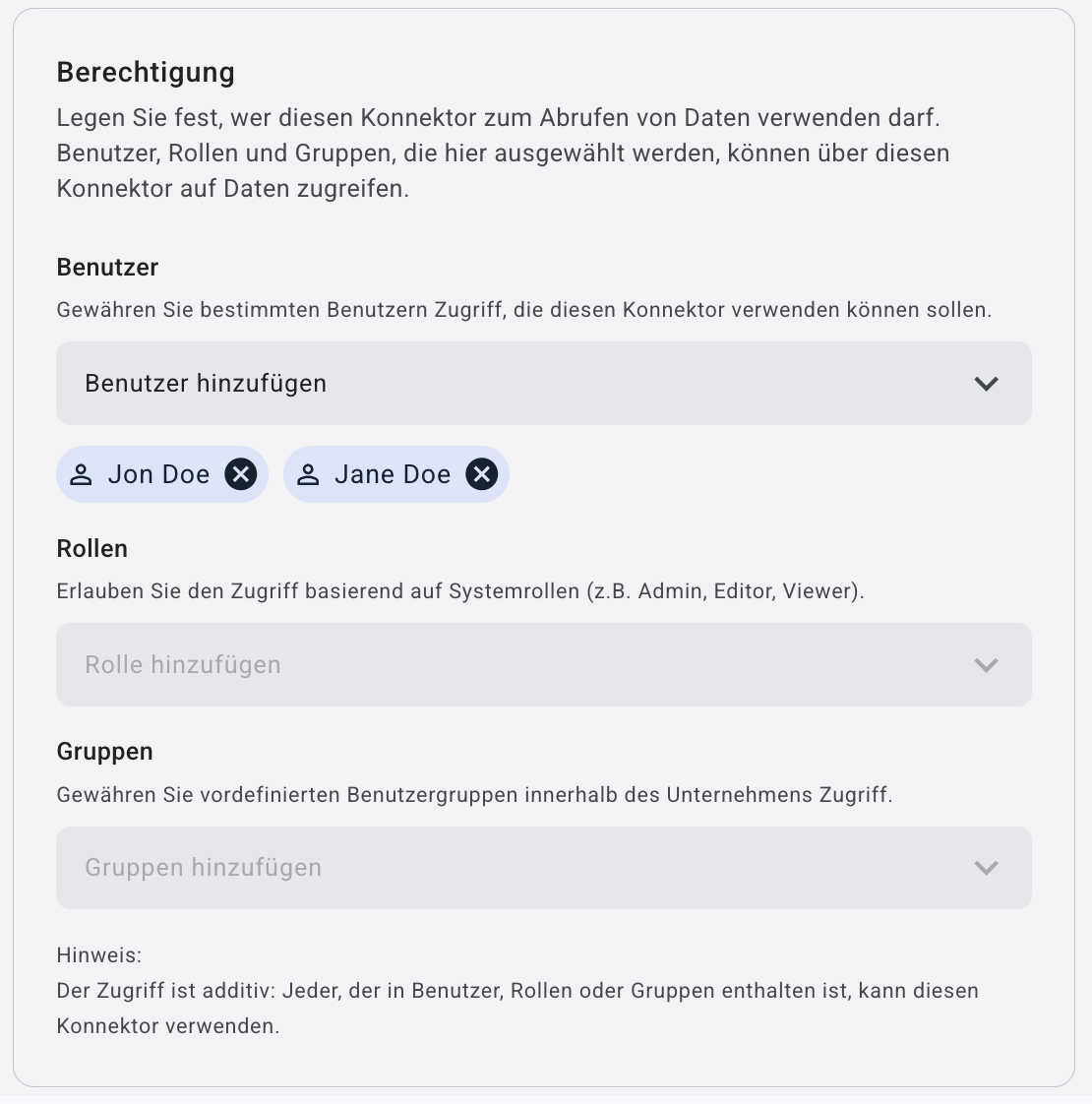
Über das Dropdown-Menü ‚Benutzer hinzufügen‘ werden Ihnen alle Nutzer angezeigt. Mit einem Klick auf den entsprechenden Namen werden sie Ihrem Konnektor hinzugefügt. Nachdem ein Benutzer hinzugefügt wurde, erscheint sein Name unterhalb des Dropdown-Menüs. Sollten Sie Benutzer entfernen wollen, können Sie dies per Klick auf das X tun.
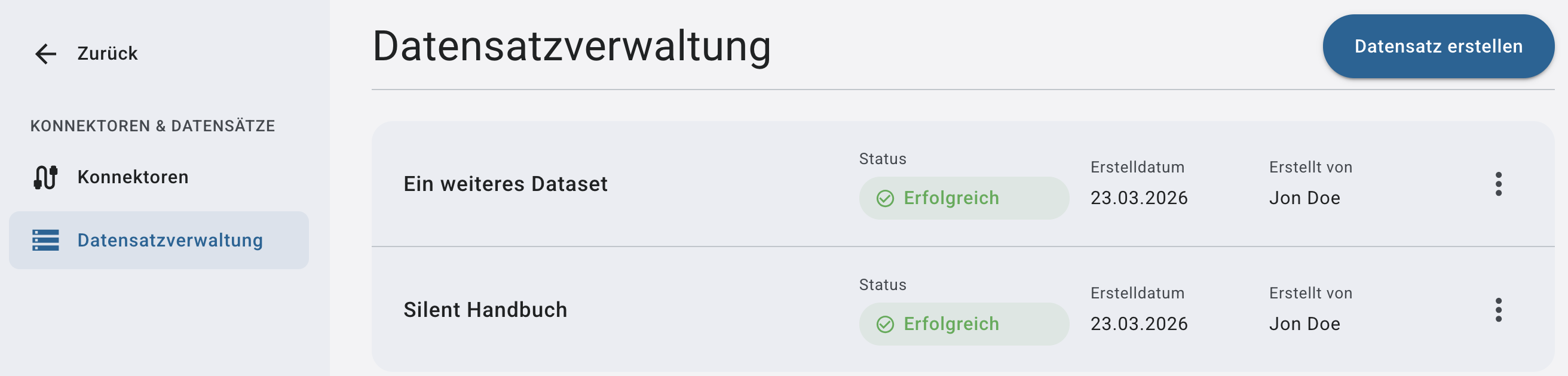
Dataset-Übersicht
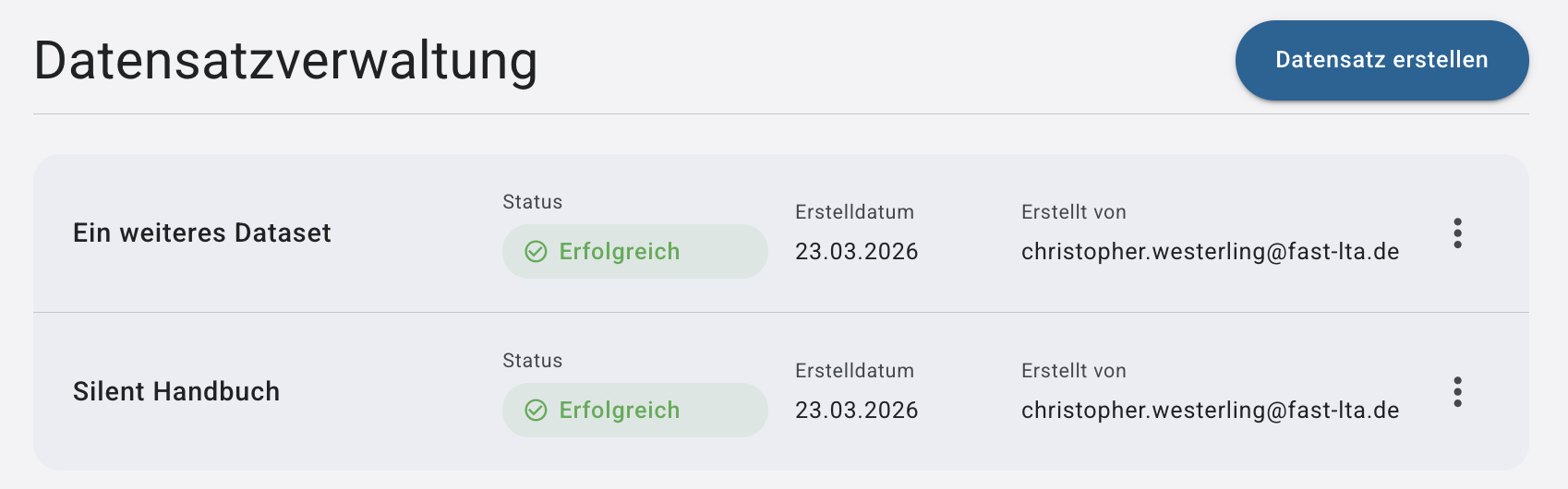
Jedes Dataset zeigt:

➤ Name
➤ Status
➤ Erstellungsdatum
➤ von welcher Person es erstellt wurde
Schritt 1: Neues Dataset erstellen
Klicken Sie auf:
➤ „Datensatz erstellen“
Es öffnet sich das Dialogfenster „Neues Dataset“.
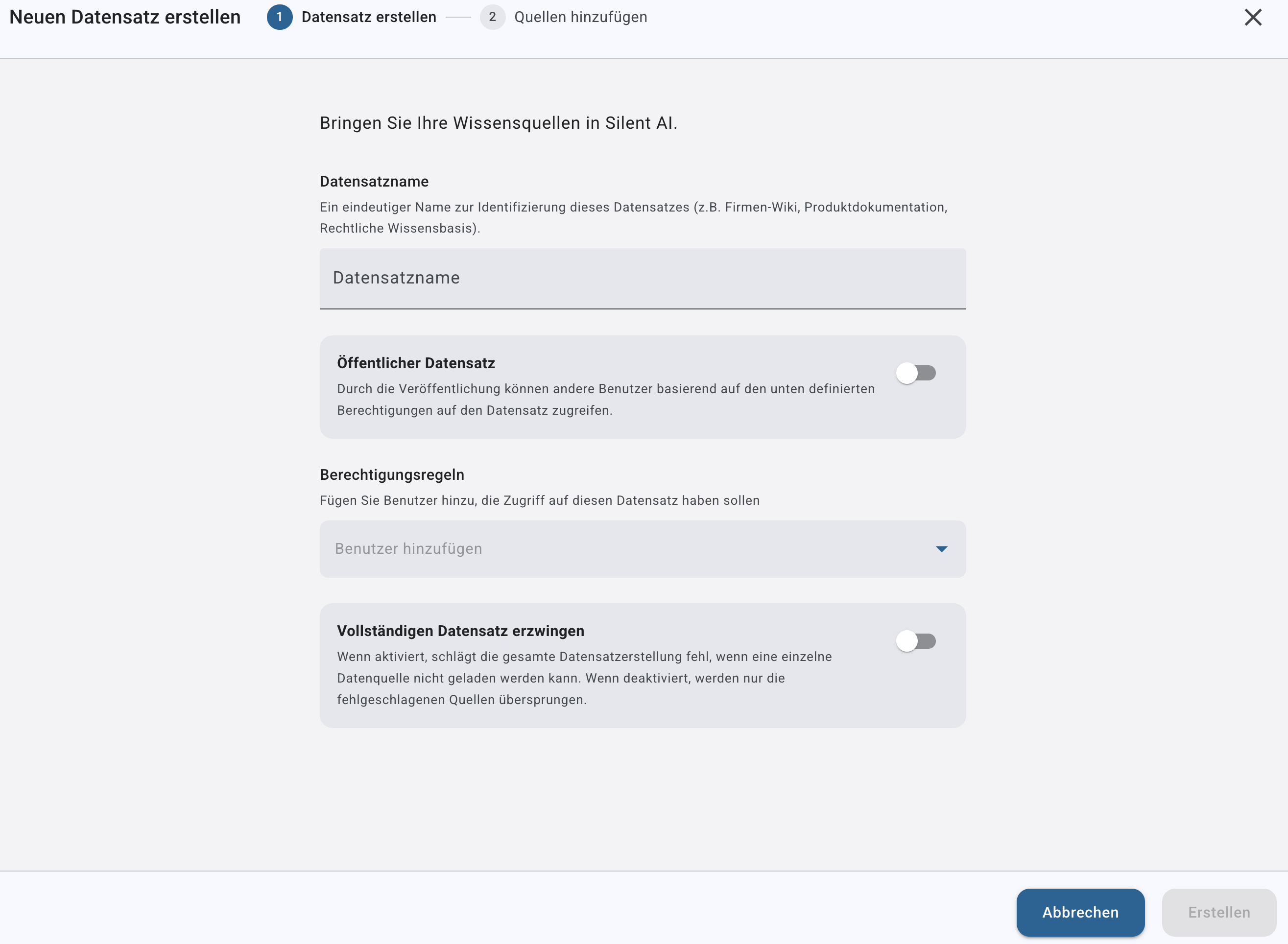
Dataset-Name vergeben
Geben Sie einen eindeutigen, sprechenden Namen ein.
Der Name sollte den inhaltlichen Zweck des Datasets widerspiegeln (z. B. „Qualitätsmanagement 2024“ oder „Technische Dokumentation SMB“).
Öffentlich / Privat Toggle
Hier können Sie einstellen, ob das Dataset für alle Personen Ihrer Organisation zur Verfügung gestellt werden soll oder ob Sie dem Dataset granulare Berechtigungen hinzufügen möchten.
Berechtigungsregeln
Sollten Sie sich für granulare Berechtigungen entschieden haben, können Sie hier Benutzer hinzufügen, die Zugriff auf das Dataset erhalten sollen.
Über das Dropdown-Menü ‚Benutzer hinzufügen‘ werden Ihnen alle Nutzer angezeigt. Mit einem Klick auf den entsprechenden Namen werden sie Ihrem Dataset hinzugefügt. Nachdem ein Benutzer hinzugefügt wurde, erscheint sein Name unterhalb des Dropdown-Menüs. Sollten Sie Benutzer entfernen wollen, können Sie dies per Klick auf das X tun
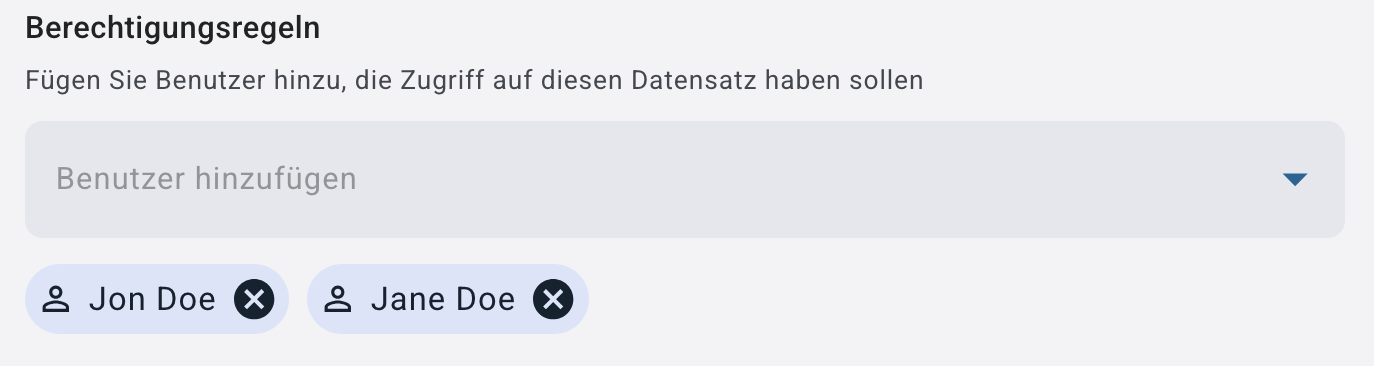
Für Nutzer ohne Administratorrechte ist die Benutzerzuweisung aktuell funktional eingeschränkt – das Dataset bleibt faktisch nur für den Ersteller zugänglich.
Gesamtes Dataset erzwingen
Mit dieser Option steuern Sie das Verhalten bei fehlerhaften Datenquellen.
Aktiviert:
Das gesamte Dataset schlägt fehl, sobald eine einzelne Datenquelle nicht geladen werden kann.
Deaktiviert:
Fehlgeschlagene Quellen werden als solche markiert (bild) und übersprungen. Diese können später granular nachgeladen werden.
Alle übrigen funktionierenden Quellen bleiben nutzbar.
Empfehlung: Sollte aktiviert werden, wenn vollständige Datenintegrität zwingend erforderlich ist.
Schritt 2: Quellen Hinzufügen
Unter „Data Sources“ legen Sie fest, welche Quellen dem Dataset hinzugefügt werden.
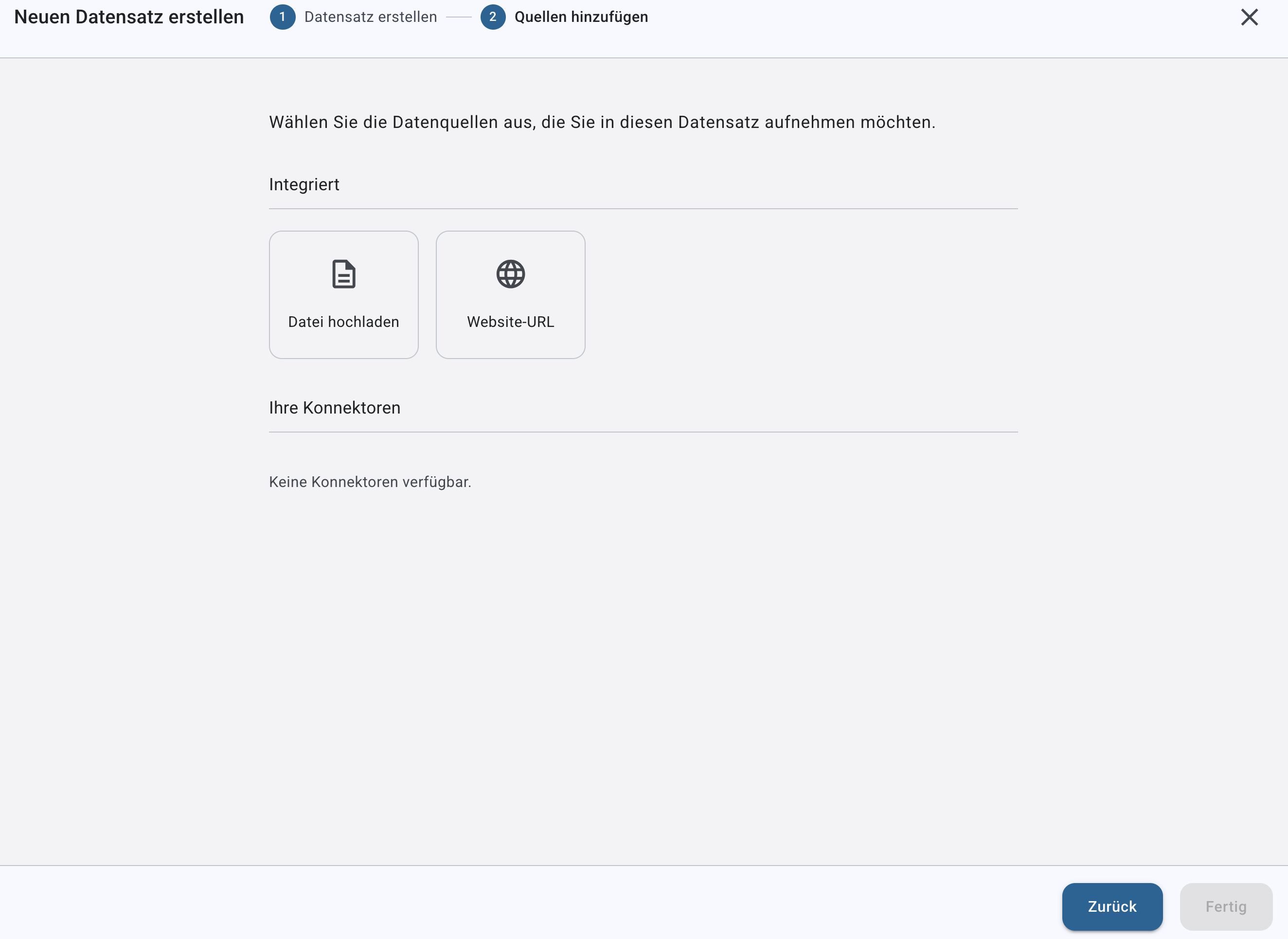
Mögliche Quellen
Je nach Systemkonfiguration stehen zur Verfügung:
➤ Zuvor eingerichtete Konnektoren (z. B. Confluence, NAS via SMB)
➤ Integrierte Quellen
-
File Upload – Dateien direkt hochladen
-
Website – Eine URL crawlen und Inhalte integrieren
Sie können beliebig viele Quellen hinzufügen. Nachdem Sie eine erste Quelle erstellt haben können die hierfür auf “+ Weitere Quelle hinzufügen” klicken.
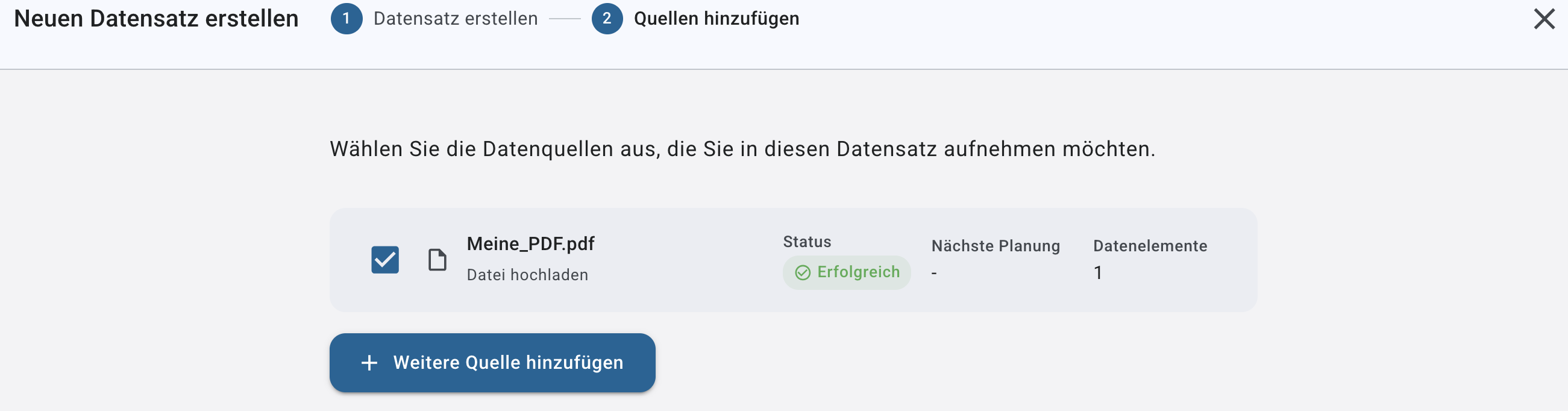
Built-in Source: File Upload
Ermöglicht das direkte Hochladen von Dateien in das Dataset. Falls gewünscht
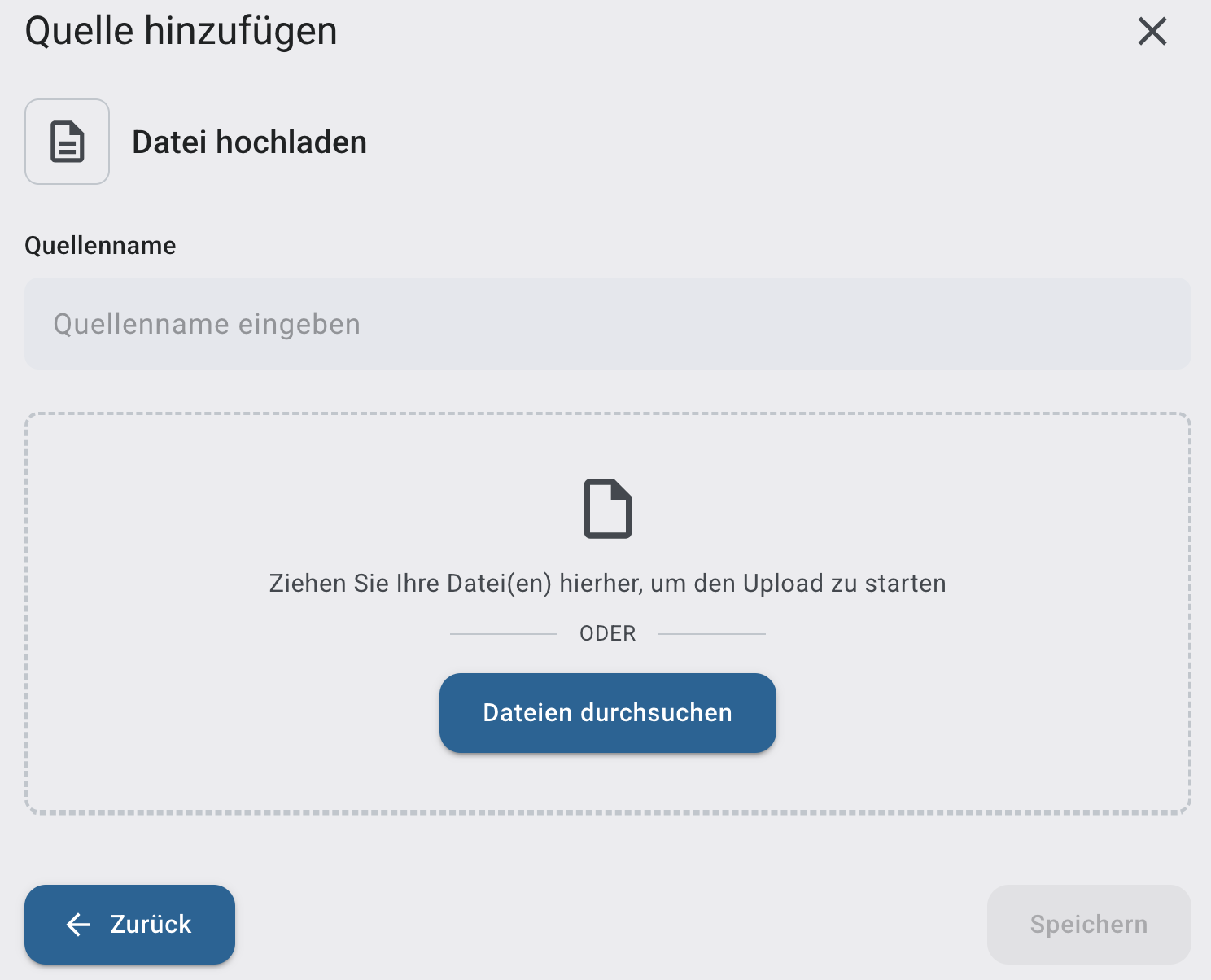
Built-in Source: Website
Ermöglicht das Crawlen einer Website-URL. Jede neue Website muss dabei über einen separaten Website-Konnektor angelegt werden.
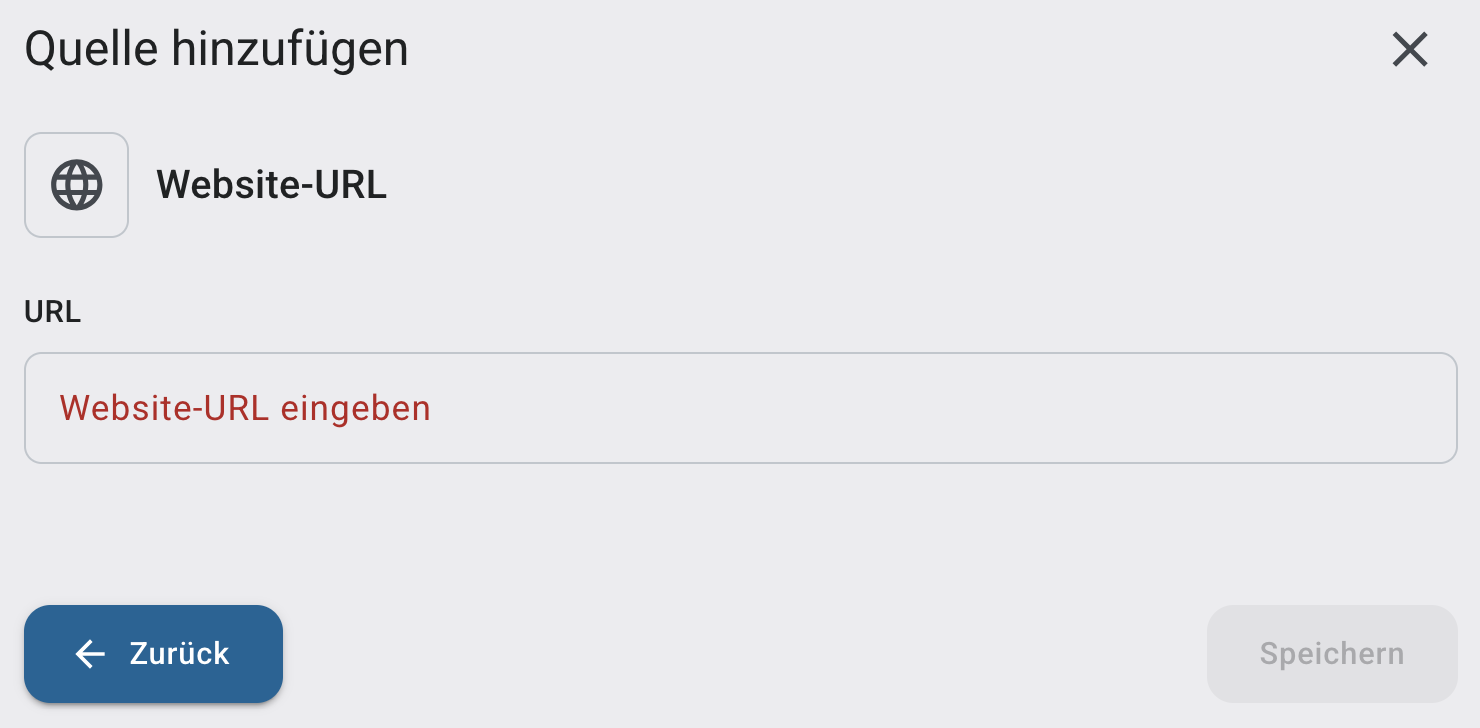
Nachdem sie eine URL eingegeben haben können Sie Speichern klicken. Die Inhalte der angegebenen Seite werden entdeckt und dem Dataset hinzugefügt.
Entdeckung (Discover)
Bei der Entdeckung werden die angebundenen Quellen analysiert und verfügbare Inhalte identifiziert.
Dabei werden:
➤ Dateien oder Seiten erkannt
➤ Neue Inhalte registriert
Beim Erstellen des Datasets erfolgt die Entdeckung von Quellen automatisch. Den Fortschritt der Entdeckung einzelner Quellen können Sie dem Status entnehmen. zB.
Sie Können während des Entdeckungsvorgangs Silent AI anderweitig nutzen
Dataset speichern
Nach Konfiguration aller Einstellungen klicken Sie auf:
➤ „Fertig“
Das Dataset erscheint anschließend in der Datensatzverwaltung.
Hinweis:
Nach dem Speichern ist das Dataset zwar angelegt, jedoch noch nicht unmittelbar für Chat-Abfragen nutzbar.
Damit Inhalte im Chat verwendet werden können, müssen die entdeckten Datenquellen verarbeitet werden.
Extraktion (Extract)
In der Datensatzverwaltung können Sie nun ihre entdeckten Quellen extrahieren. Bei der Extraktion werden die entdeckten Inhalte verarbeitet und für die Nutzung im Chat aufbereitet.
Dabei werden:
➤ Dokumente geladen
➤ Texte extrahiert
➤ Inhalte strukturiert
➤ Daten für Abfragen indexiert
➤ Änderungen an bestehenden Quellen erfasst und aktualisiert
Erst nach erfolgreicher Extraktion stehen die Inhalte im Chat zur Verfügung.
Ausführungsmöglichkeiten
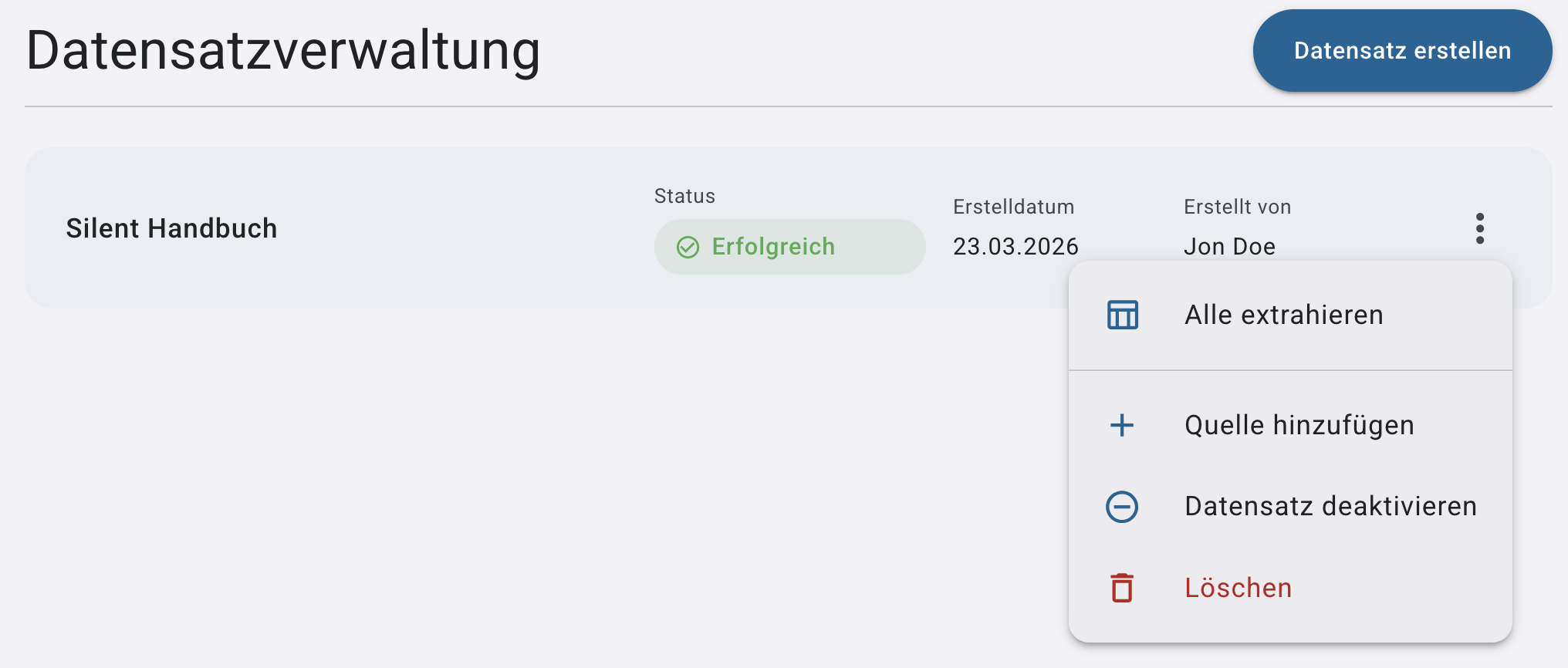
Für das gesamte Dataset:
➤ Über das Dataset-Menü (⋮):
„Alle extrahieren“
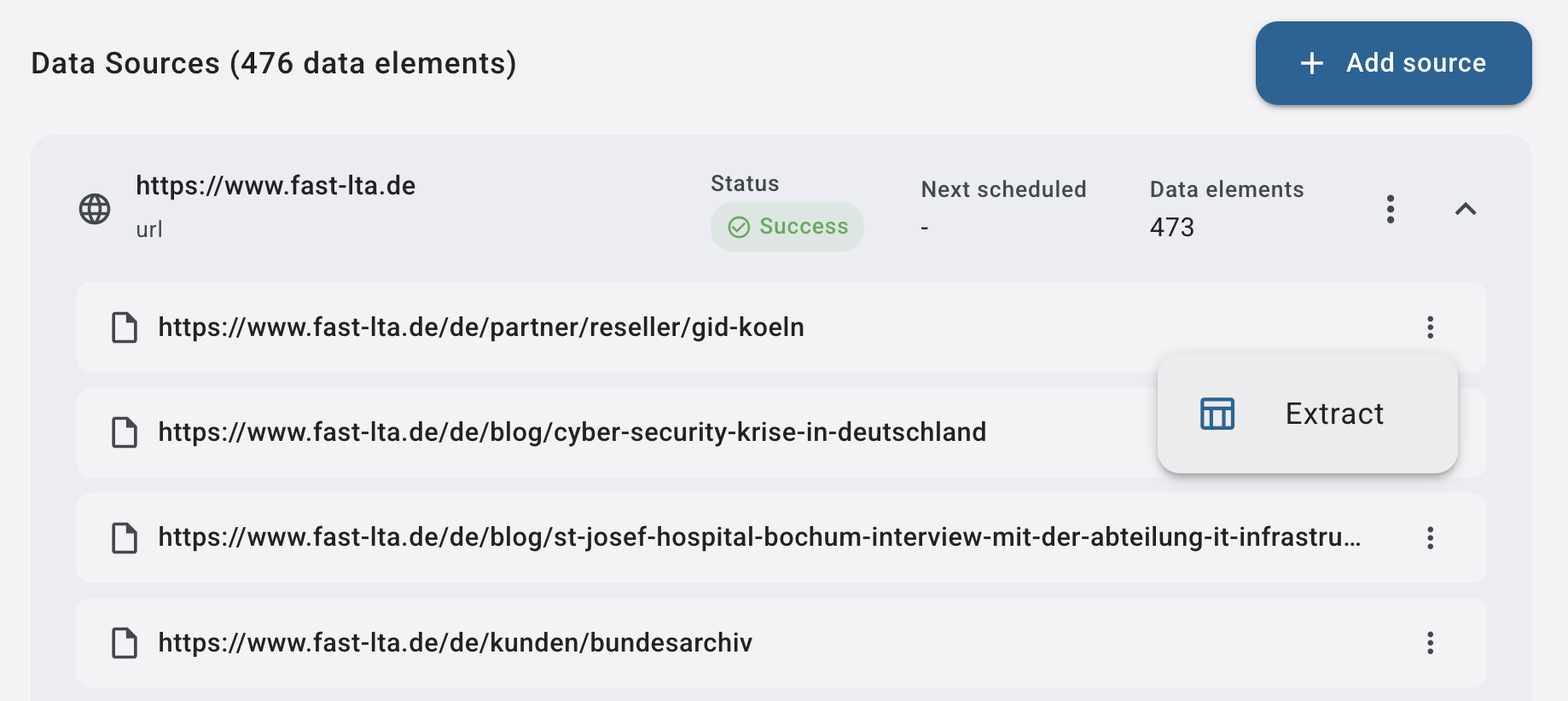
Für einzelne Quellen:
➤ Über das Kontextmenü einer spezifischen Quelle in der Detailansicht des Datasets:
Extraktion nur für eine einzelne Quelle
Sie Können während des Entdeckungsvorgangs Silent AI anderweitig nutzen
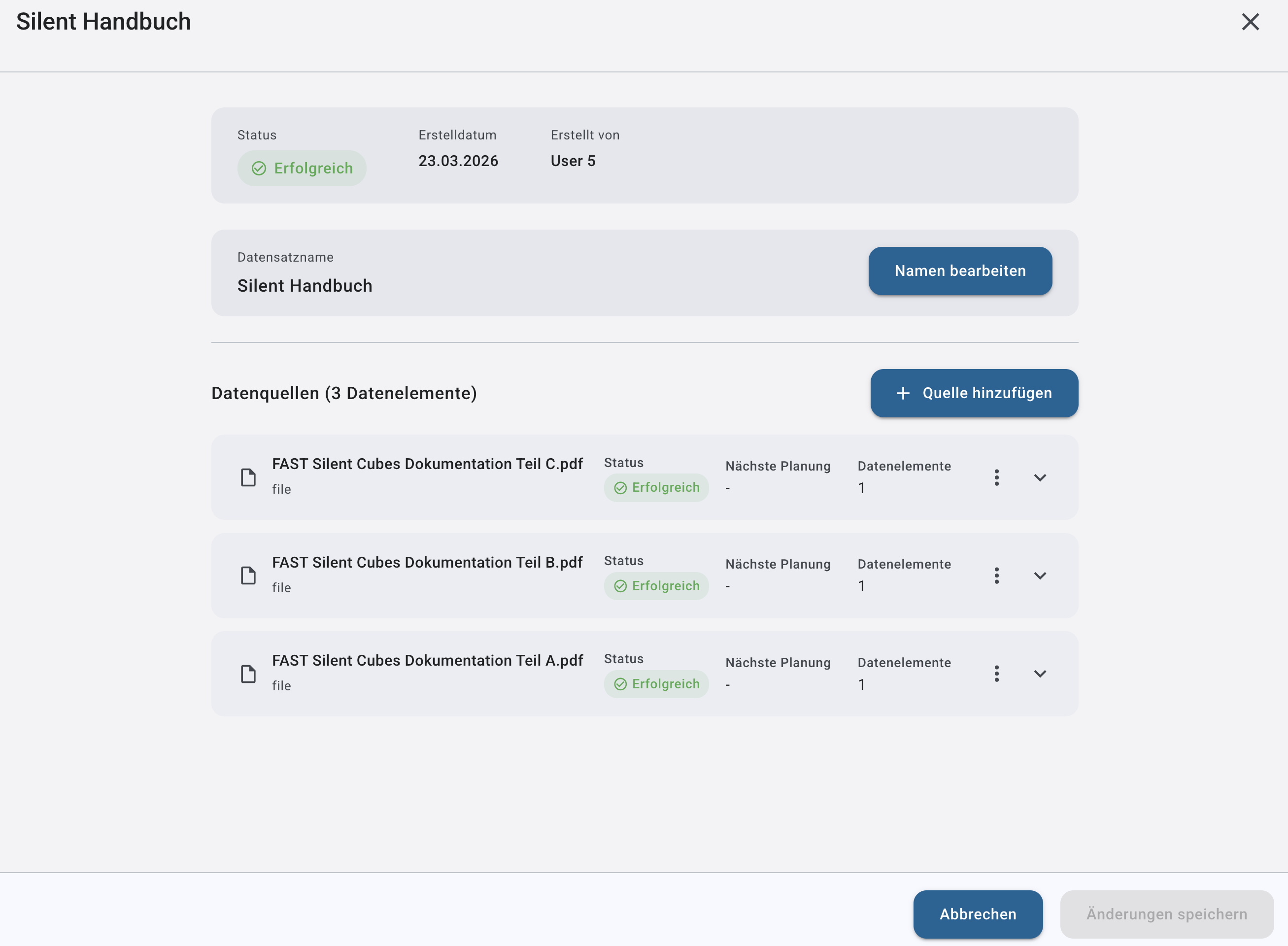
Detailansicht
Die Detailsansicht für Datensätze bietet die möglichkeit den Datensatz nachträglich zu bearbeiten. Der Name des Datensatzes den Sie Momentan ausgewählt haben ist dabei oben links angezeigt.
Sie können hier:
➤ Namen des Datensatzes anpassen
➤ Nachträglich Quellen Hinzufügen
➤ Granulare einsicht in den Extraktionsprozess einzelner Quellen erhalten
➤ Einzelne Quellen Erneut extrahieren (zB. fehlgeschlagene / neu hinzugefügte)
Erweiterung bestehender Datasets
Datasets sind nicht statisch und können jederzeit erweitert werden.
Mögliche Erweiterungen:
➤ Neue Datenquellen hinzufügen
➤ Weitere Dateien hochladen
➤ Zusätzliche Konnektoren anbinden
Nach dem Hinzufügen neuer Quellen müssen diese erneut:
➤ Entdeckt
➤ Extrahiert
werden, damit sie im Chat verfügbar sind.
Bereits vorhandene und extrahierte Inhalte bleiben dabei erhalten.
Typischer Aktualisierungs-Workflow
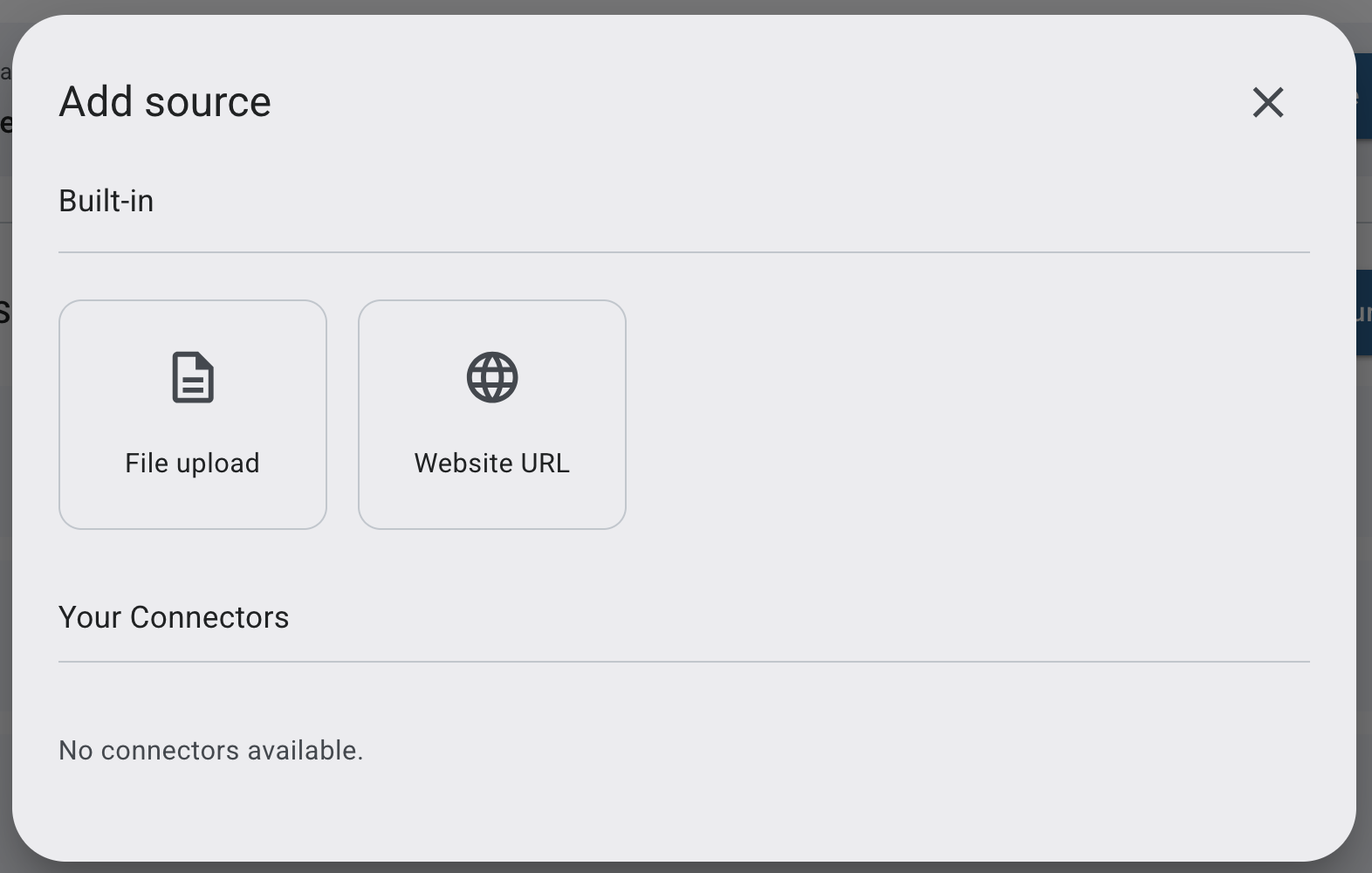
1.) Neue Quelle oder Datei hinzufügen wenn gewünscht: Klicken Sie hierfür den “+ Quelle Hinzufügen” Button. Das Hinzufügen erfolgt dabei identisch zum Hinzufügen von Datenquellen bei der ursprunglichen Erstellung des Datensets.
Je nach Systemkonfiguration stehen zur Verfügung:
➤ Zuvor eingerichtete Konnektoren (z. B. Confluence, NAS via SMB)
➤ Integrierte Quellen
-
File Upload – Dateien direkt hochladen
-
Website – Eine URL crawlen und Inhalte integrieren
2.) Extraktion durchführen: Hierfür Können die Entweder Alle der Entdeckten Elemente Extrahieren
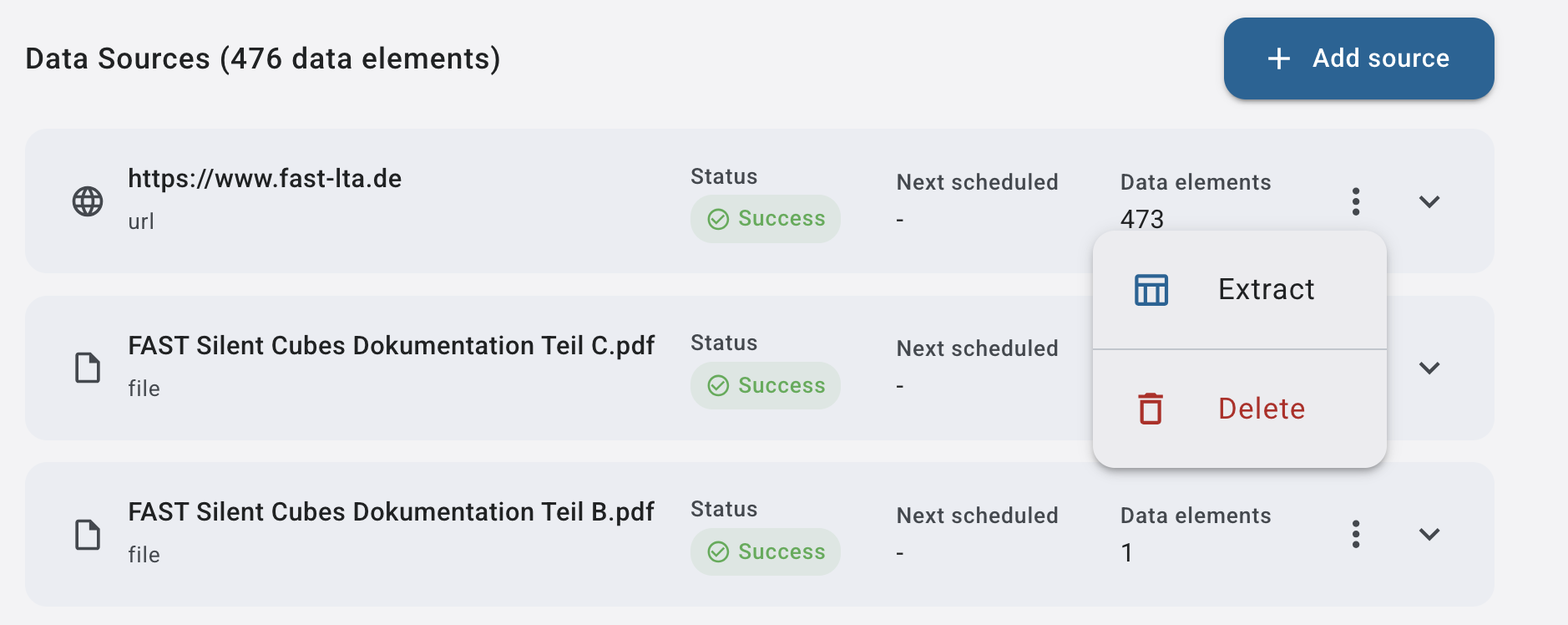
oder eine Datenquelle ausklappen und nur einzelne Elemente einer Quelle extrahieren.
Öffentlich vs. Privat
Datasets unterscheiden sich hinsichtlich ihrer Sichtbarkeit und Zugriffsberechtigung.
Private Datasets
Private Datasets, die Sie selbst erstellen:
➤ Sind ausschließlich für Sie sichtbar
➤ Können nur von Ihnen im Chat ausgewählt werden
➤ Sind für andere Nutzer nicht einsehbar
Zusätzliche Private Datasets mit definierten Berechtigungen
Administratoren können private Datasets erstellen, die nur für bestimmte Personen sichtbar sind.
In diesem Fall:
➤ Ist das Dataset nur für die explizit hinterlegten Nutzer sichtbar
➤ Erscheint es in der Dataset-Liste nur bei diesen Personen
➤ Ist es für alle anderen Nutzer vollständig unsichtbar
Die berechtigten Nutzer sind im Dataset unter „Berechtigungsregeln“ explizit aufgeführt.
Nur dort angegebene Personen können das Dataset sehen und verwenden.
Dies gewährleistet eine kontrollierte, rollenbasierte Freigabe sensibler Inhalte.
Öffentliche Datasets
Öffentliche Datasets sind unternehmensweit sichtbar.
Sie:
➤ Können von allen berechtigten Nutzern eingesehen werden
➤ Stehen allen Nutzern zur Auswahl im Chat zur Verfügung
Daten aus Quellen mit Zugriffsbeschränkungen übernehmen diese auch in öffentlichen Datasets. Das Teilen eines Datasets umgeht nicht die Zugriffsbeschränkungen!